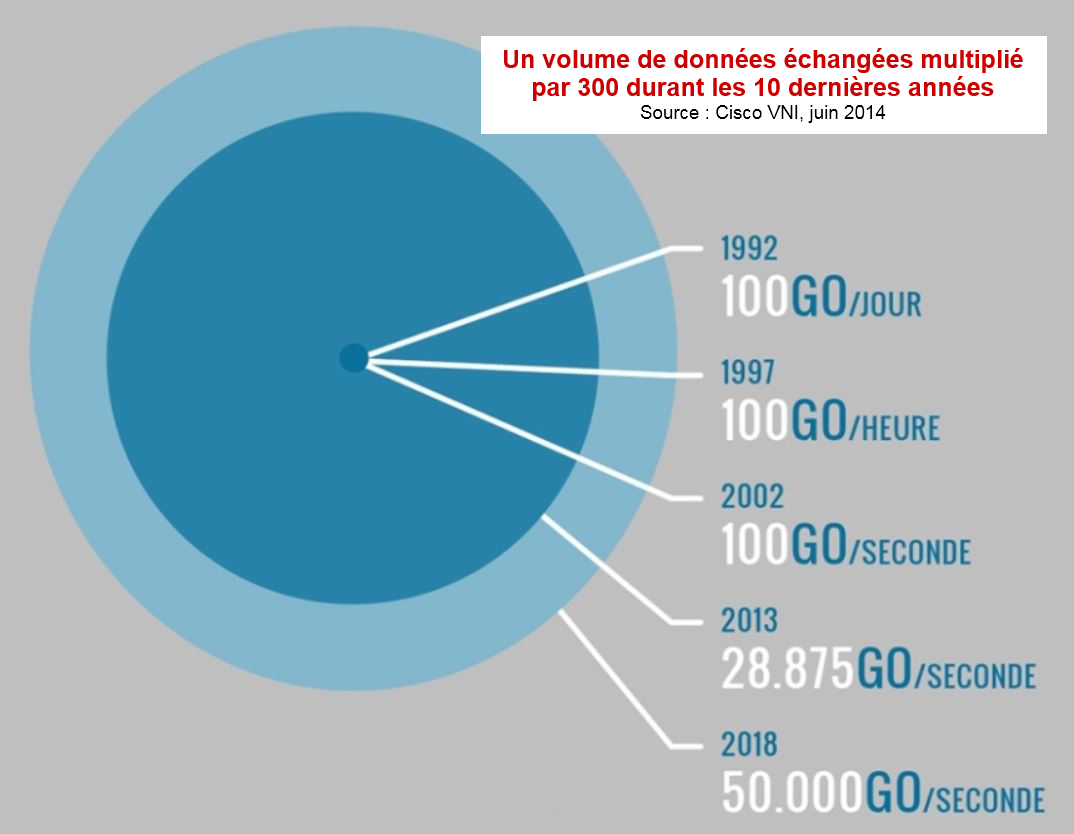
Depuis son annonce à la mi-mars jusqu’à son approbation ce 5 mai par l’Assemblée Nationale avec une très large majorité, le projet de loi relatif au renseignement a fait l’objet de nombreux débats entre ses partisans et ses détracteurs.
Pour mémoire, ce projet, né après l’attaque de Charlie Hebdo, entend donner plus de moyens aux services de renseignement : accès direct aux « réseaux des opérateurs » (télécoms, services en ligne, hébergeurs) pour surveiller une personne suspecte, utilisation d’outils comme les « IMSI Catchers » pour intercepter les appels téléphoniques des mobiles, installation de « boîtes noires » chez les acteurs du numérique pour repérer automatiquement les comportements à risque. L’utilisation de ces dispositifs de surveillance sera contrôlée par une autorité indépendante, la Commission nationale de contrôle (CNCTR).
Une telle perspective n’a pas semblé émouvoir plus que ça le grand public. Selon un sondage CSA, près de 2/3 des Français se disaient « favorables à une limitation de leurs libertés individuelles sur Internet au nom de la lutte contre le terrorisme ». Valérie Peugeot, vice-présidente du Conseil national du numérique, explique les raisons de cette apathie par un manque de sensibilisation (« il n’y a rien de plus difficile que de se rebeller contre l’invisible »). D’ailleurs, dans le même sondage CSA, moins de 30% des Français affirmaient connaître le contenu du projet…
En revanche, les acteurs et observateurs du monde numérique en analysent depuis plus d’un mois les tenants et les aboutissants, et leurs avis sont quasi unanimement hostiles à la Loi sur le Renseignement. Une phrase de la tribune libre rédigée par un collectif d’hébergeurs début avril résume l’ensemble de leurs récriminations : « Le projet de loi du gouvernement est non seulement liberticide, mais également anti-économique, et pour l’essentiel, inefficace par rapport à son objectif. »
Un projet liberticide adopté sans débat démocratique
L’argument relatif à la violation des libertés individuelles est le plus soulevé. Dès l’annonce du projet, le Conseil national du numérique s’est inquiété « d’une extension du champ de la surveillance », invitant le gouvernement « à renforcer les garanties et les moyens du contrôle démocratique ». De leur côté, le commissaire aux droits de l’homme du Conseil de l’Europe Nils Muižnieks, et les rapporteurs des Nations Unies sur les droits de l’homme Michel Forst et Ben Emmerson ont cosigné une tribune libre critiquant ce projet, « parce qu’il autorise le recours à des méthodes de surveillance qui font peser une menace sérieuse sur le droit au respect de la vie privée », « parce qu’il permet la mise en œuvre de ces mesures intrusives sans un contrôle préalable indépendant », et « parce qu’il pourrait aggraver les tensions sociales en autorisant un contrôle indiscriminé de personnes qui ne sont pas soupçonnées d’activité terroriste ». Par la voix de sa présidente Isabelle Falque-Pierrotin, la CNIL s’est, pour sa part, déclarée préoccupée par la question du devenir des données collectées.
Le son de cloche est le même du côté des intellectuels. Pour le philosophe et écrivain Eric Sadin, « Cette loi est répréhensible. C’est une faute, c’est une faute politique, c’est une faute sociétale, c’est une faute éthique et c’est une faute juridique, ça fait beaucoup ! ». Antoinette Rouvroy, chercheuse au Fonds de la Recherche Scientifique belge, qualifie ce projet de « fantasme de maîtrise de la potentialité », reposant sur « l’idée que grâce au calcul, grâce à l’analyse des données en quantité massive, grâce au big data, on va pouvoir vivre dans un monde non-dangereux ».
« Etonné et inquiété » par cette loi, l’historien et sociologue Pierre Rosanvallon estime, pour sa part, qu’elle a été « très mal préparée et très mal écrite » et qu’elle n’a « aucune colonne vertébrale ». Enfin, figurant au rang des premiers et des plus farouches opposants à la Loi Renseignement, La Quadrature du Net dénonce, au-delà du contenu du projet en lui-même, la rapidité avec laquelle il est mis en place, et cela sans débat démocratique.
Le recours au big data inadapté à la lutte contre le terrorisme ?
Comme d’autres observateurs, Grégoire Chamayou, chargé de recherche au CNRS, conteste l’efficacité d’un recours au big data à des fins de surveillance : « Contre les attentats de demain, croire que les scénarios de ceux d’hier seront utiles, c’est comme chercher une aiguille dans une botte de foin, alors que la couleur et la forme de l’aiguille ne cessent de changer. Même à supposer que le terrorisme présente des signatures repérables par data mining – ce qui est pour le moins hasardeux –, pareil système va engendrer pléthore de suspects, dont une écrasante majorité de fausses pistes – et ceci par millions. »
Jean-Marie Delarue, Président de la Commission nationale de contrôle des interceptions de sécurité (CNCIS) ne dit pas autre chose, goûtant peu les « techniques évidentes de pêche au chalut » induites par ce projet. Il craint par ailleurs que la CNCTR ne soit qu’un « colosse aux pieds d’argile, un contrôleur dépendant d’un tiers pour accéder aux données qu’il est chargé de contrôler ». Selon lui, plus qu’un renforcement, « il y a donc un affaiblissement très net du contrôle ».
Un risque d’affaiblissement économique des acteurs du numérique français
Concernés au premier chef par la mesure des « boîtes noires », les hébergeurs français y ont vu une menace directe de leurs intérêts : « En tout, 30 à 40 % de notre chiffre d’affaire est réalisé » avec des clients étrangers qui « viennent parce qu’il n’y a pas de Patriot Act en France, que la protection des données des entreprises et des personnes est considérée comme importante. Si cela n’est plus le cas demain en raison de ces fameuses boîtes noires, il leur faudra entre 10 minutes et quelques jours pour quitter leur hébergeur français ». Les hébergeurs craignent par ailleurs de voir les entreprises françaises les quitter pour l’étranger : « ce sont des milliers d’emplois induits par le cloud computing, le big data, les objets connectés ou la ville intelligente que les start-ups et les grandes entreprises iront créer ailleurs ».
Face à la menace des hébergeurs de « déménager leurs infrastructures, investissements et salariés là où leurs clients voudront travailler avec eux », le gouvernement n’a pas tardé à réagir et à leur proposer l’amendement n°437. Il leur permet de faire eux-mêmes la distinction entre les données de connexion, que les services de renseignement pourront consulter sous réserve d’une validation préalable par la CNCTR, et les contenus, qui resteront privés. Cet amendement semble avoir satisfait les hébergeurs, même si Valentin Lacambre, pionnier de la liberté d’expression sur Internet, a décidé de fermer son service Altern.org, affirmant : « Pour nous, un seul jour sous écoute globale est un jour de trop ».
Quoi qu’il en soit, malgré les centaines de signatures des acteurs du numérique sur la Pétition NiPigeonsNiEspions, la Loi Renseignement a désormais été adoptée par l’Assemblée Nationale. Voyons maintenant quel sera l’avis du Conseil Constitutionnel, que François Hollande s’est engagé à saisir.