Et si on partait du point de départ ? Les données sont en effet ce qui donne un sens à la notion même de Big Data – ou mégadonnées, selon les recommandations linguistiques de la Délégation Générale à la Langue Française et aux Langues de France.
Selon la définition, faisant désormais autorité, énoncée par Gartner en 2012, les données du Big Data présentent trois caractéristiques majeures, que les nouvelles technologies de traitement de l’information permettent de prendre en compte : leur Volume, leur Variété et leur Vélocité. La littérature marketing y rajoute parfois 2 V complémentaires, la Véracité (la qualité et la fiabilité des données) et la Valeur (leur caractère monétisable).
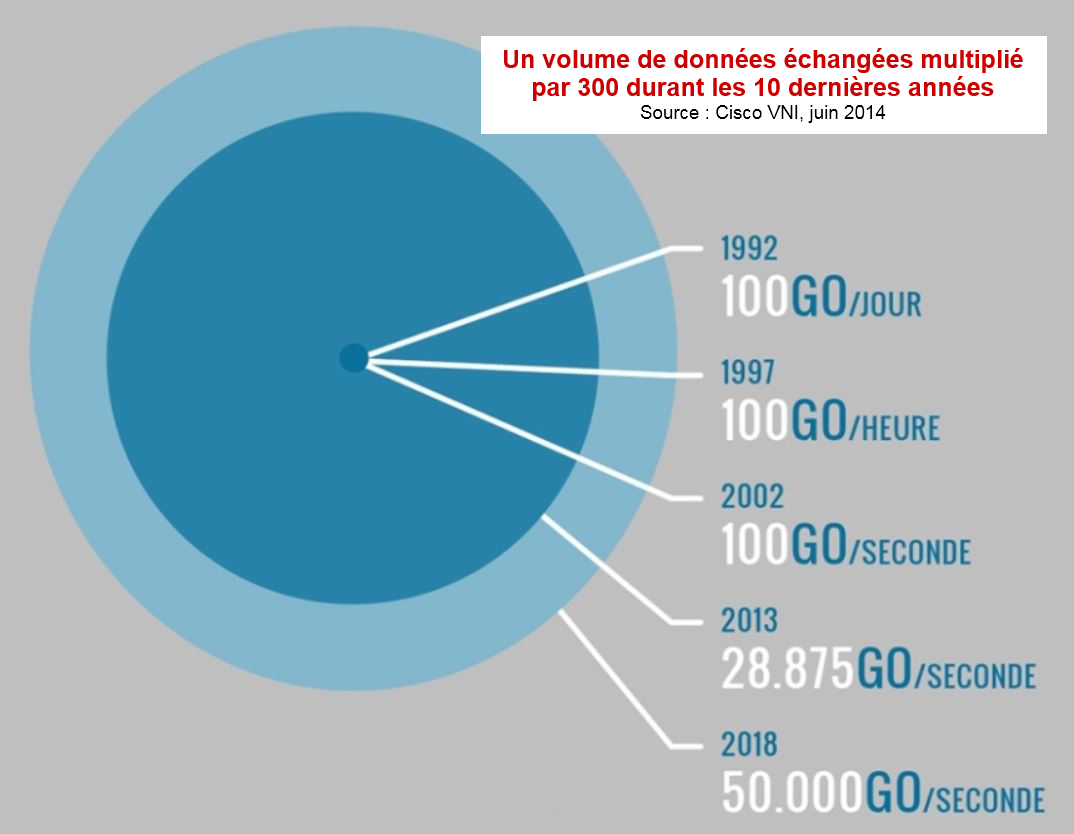
De fait, depuis le début de l’ère numérique, le Volume de données existantes a connu une croissance exponentielle. Si cette notion peut être appréhendée plus aisément à travers des infographies comme celle de VoucherCloud, elle peut être résumée en quelques chiffres : il y a un peu plus de 10 ans, le trafic Internet était de l’ordre de 100Go de données échangées par seconde (soit autant qu’en un jour entier 10 ans auparavant). Aujourd’hui, nous avons dépassé les 30 000Go par seconde et nous devrions atteindre les 50 000Go d’ici à 2018. Conséquence de cette explosion des volumes, 90% des données aujourd’hui existantes datent de moins de 2 ans.
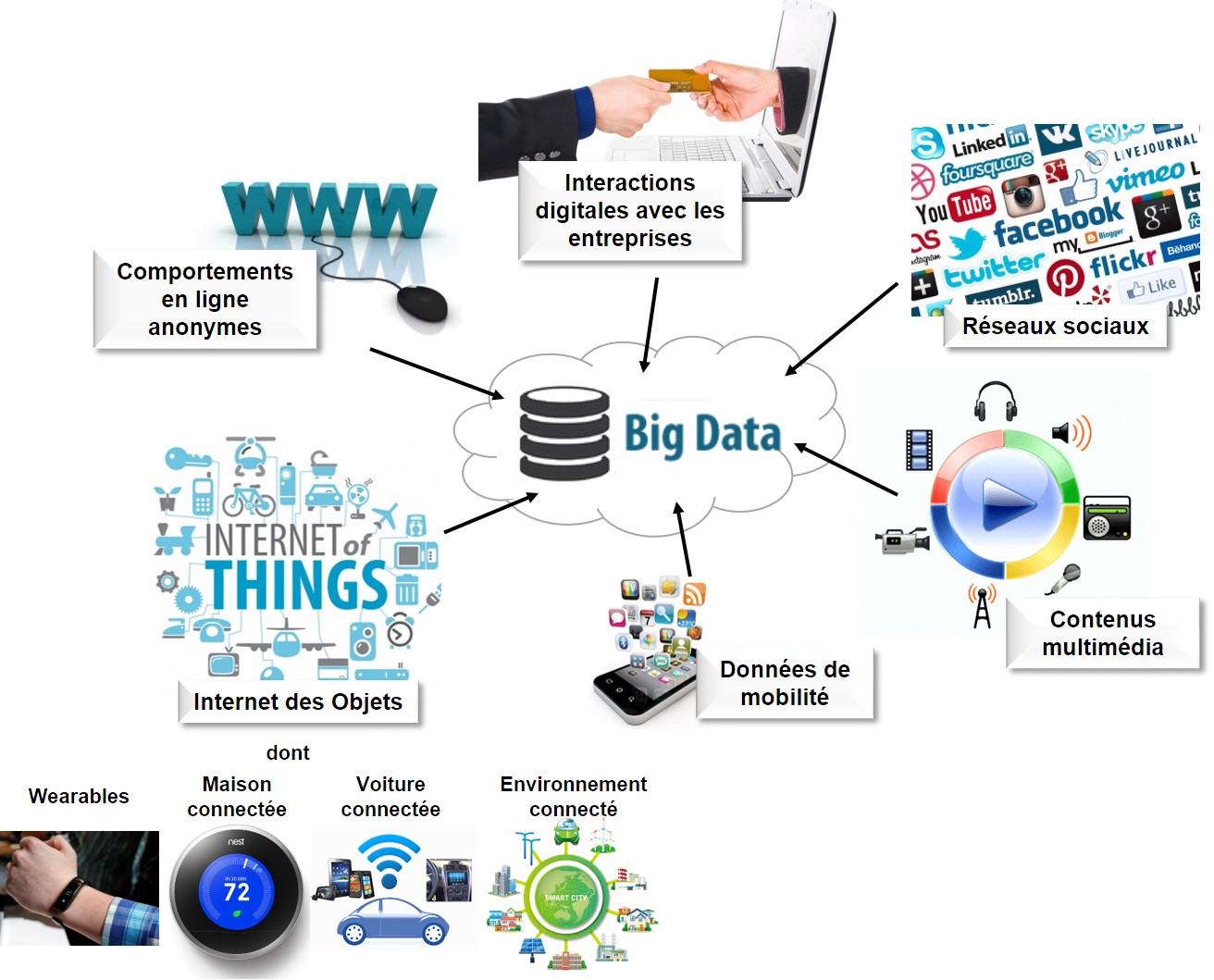
Au-delà de l’augmentation du nombre d’utilisateurs de solutions IT et de la croissance des volumes opérationnels de données, c’est surtout la Variété de plus en plus grande des sources, liée à l’évolution des usages et des technologies de traitement de l’information, qui justifie cette croissance exponentielle. Hier, les données utilisables par les acteurs du monde socio-économique se limitaient à des informations hautement formatées. Aujourd’hui, le Big Data permet de traiter tout type de donnée, dans sa forme originelle, non structurée, multipliant ainsi les sources.
Les comportements en ligne – plus ou moins anonymes –, comme la navigation, la recherche et l’utilisation des outils de communication sont les premiers qui viennent à l’esprit. Les informations et comportements clairement identifiés sont eux aussi « trackés », à l’image de toutes les interactions en ligne avec les entreprises, telles que le remplissage de formulaires, les réactions à l’e-mailing, les objets et services achetés, les transactions financières, l’utilisation des coupons de fidélité, ou les échanges liés au SAV : tous les clients d’Amazon peuvent constater qu’aucun de leurs faits et gestes sur ses sites n’échappe au plus connu des e-commerçants. Ce qui change, c’est que toutes les entreprises s’y mettent, de façon parfois plus discrète mais pas moins intensive. N’oublions pas les réseaux sociaux, puisqu’il semblerait, selon une récente étude, que Facebook nous connaisse mieux que nos meilleurs amis. Les contenus, photos, vidéos, musique, articles de blogs, que nous créons, lisons, partageons et auxquels nous réagissons n’échappent pas non plus au Big Data. Et bien sûr, cela fonctionne aussi en mobilité, grâce à nos chers smartphones et autres tablettes, qui dévoilent par ailleurs des informations concernant notre usage des applications ainsi que nos données de géolocalisation.
C’était tout – et déjà beaucoup – jusqu’à l’émergence de l’Internet des Objets. Désormais, notre corps, « augmenté » par les « wearables » tels que les montres ou les bracelets connectés, peut révéler des informations concernant notre santé ou notre activité physique. De même, notre maison, équipée de solutions connectées relatives à la sécurité, à la gestion énergétique ou au simple confort peut en dire beaucoup sur nos habitudes, tout comme notre voiture, possiblement connectée elle aussi, au-delà du seul GPS. Nous voilà donc 100% connectés dans un environnement qui ne l’est pas moins et livre, en open data, ses propres informations, des statistiques démographiques et économiques aux données nécessaires au bon fonctionnement des services publics (transport, éducation, vie culturelle, etc.).
Déjà évoquée dans ces colonnes, l’excellente web-série interactive Do Not Track fournit des illustrations assez édifiantes de la façon dont toutes nos données sont collectées.
Nombreuses et variées, ces données sont de plus en plus souvent exploitées en temps réel, justifiant le 3ème V, dédié à la Vélocité.
Il n’est pas étonnant que ces données en nombre infini, qui décrivent de plus en plus précisément nos comportements et leur évolution, soient désormais considérées comme le moteur principal de l’économie numérique. Le Web en témoigne d’ailleurs, filant généreusement les métaphores aurifère et pétrolifère. En offrant des opportunités d’analyse plus larges et plus fines, le Big Data ouvre de nouveaux horizons, non seulement au confort des utilisateurs, mais aussi à la prise de décision des entreprises et des organisations. Pour quels usages ? Avec quels intérêts et quels risques ? La suite au prochain numéro…
One thought on “Big Data : au commencement était la donnée”