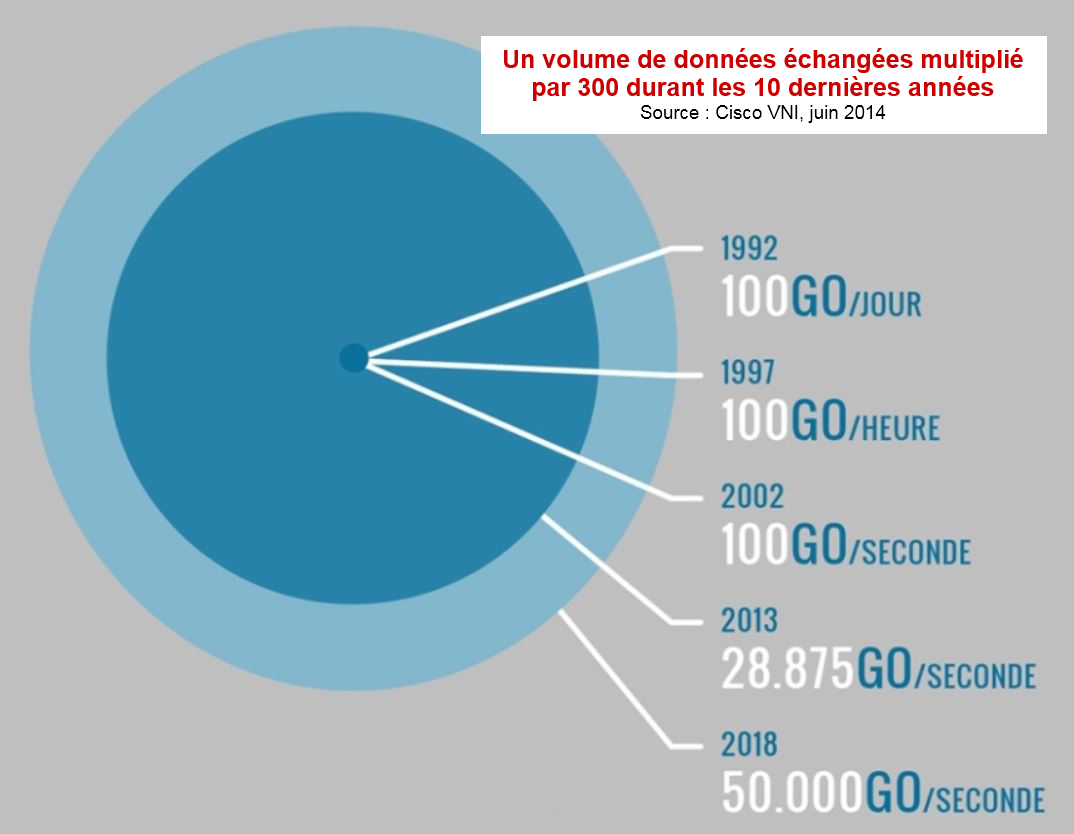
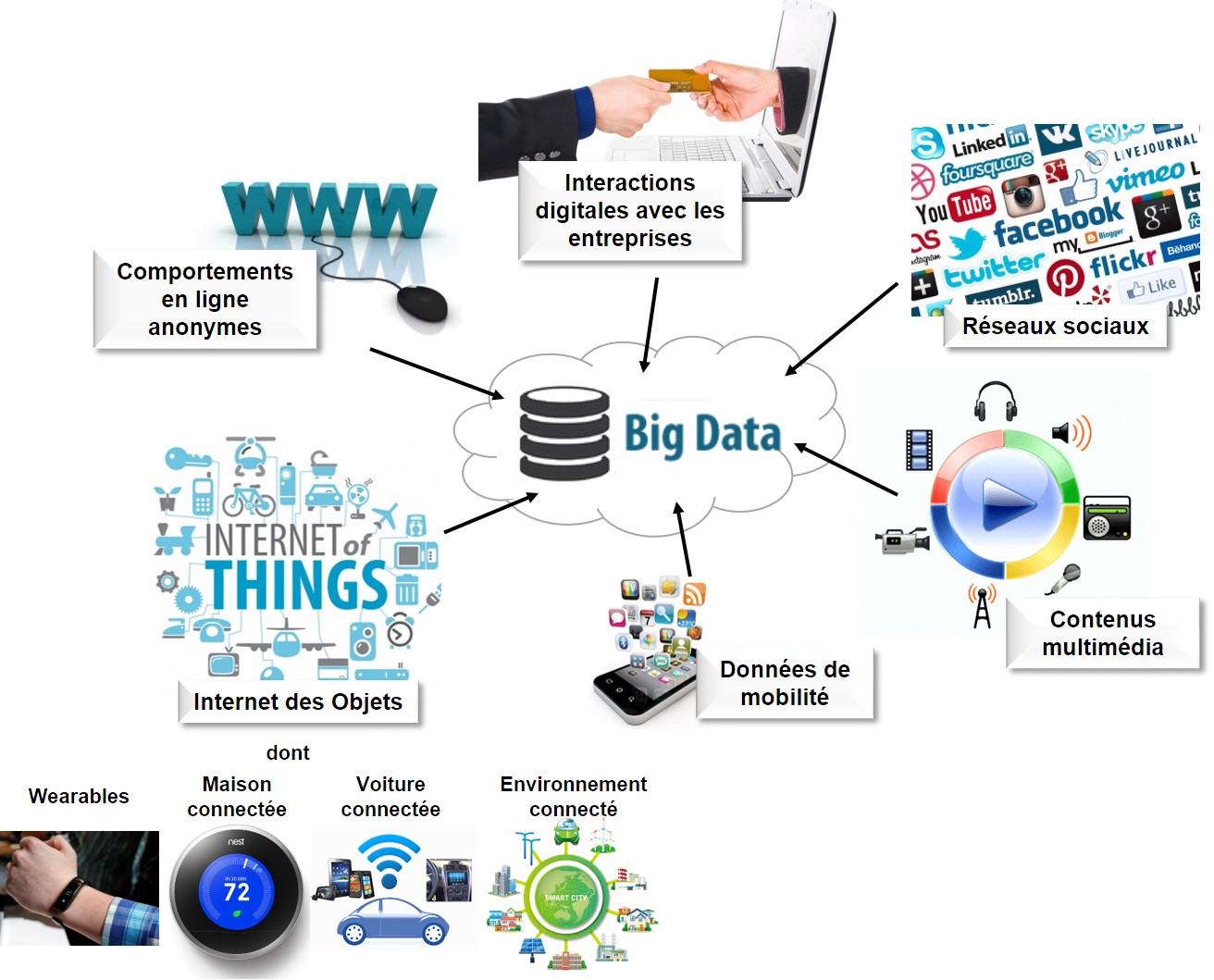
Depuis des décennies, les marketeurs analysent les données clients à leur disposition, avec l’objectif de vendre plus et, éventuellement, mieux, c’est-à-dire pendant plus longtemps dans une logique de fidélisation. L’émergence récente du Big Data est venue décupler leur capacité d’analyse et, partant, leurs possibilités de réaction, voire d’anticipation des comportements de leurs clients. De fait, à l’instar de celle de Gartner, la plupart des études estiment qu’entre 50% et 60% des projets Big Data sont liés à l’expérience client au sens large.
Ainsi, en collectant des données lorsque ses clients sont exposés à ses campagnes de communication, achètent ses produits ou souscrivent à ses services, naviguent sur ses sites Web ou interagissent avec elle, une entreprise est à même de mieux les connaître. Elle peut ainsi adapter son offre, sa stratégie et ses outils de vente et de relation client, afin de faire vivre à ses clients une expérience en adéquation avec leurs attentes.
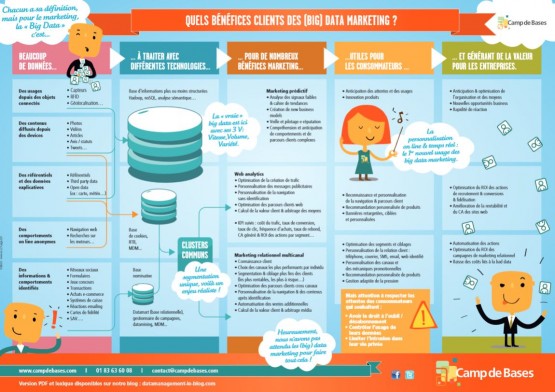
Une fois mise en place la fameuse vision à 360° de ses clients, l’entreprise est susceptible d’obtenir de « nombreux bénéfices marketing », « utiles pour les consommateurs » et « générant de la valeur », comme le montre l’infographie de l’agence Camp de Bases.
Selon notre analyse, reposant sur une étude Markess, trois grands types d’objectifs président aux actions des directions marketing en matière de Big Data:
- Vendre plus, notamment en ligne, en personnalisant le parcours digital des clients, de leur navigation sur les sites aux messages publicitaires qui leur sont présentés, pour leur proposer les offres les plus adaptées grâce à une segmentation et à un ciblage plus fins ;
- Vendre mieux en simplifiant la relation client, grâce à une stratégie adaptée à chaque canal d’interaction (téléphone, e-mail, SMS, Web, réseaux sociaux) et à une optimisation des parcours inter canaux ;
- Anticiper, en analysant tendances lourdes et signaux faibles pour se préparer aux évolutions comportementales des clients, de façon collective avec, par exemple, de nouveaux produits ou services, ou de façon individualisée, avec notamment la prévention des risques de rupture de la relation client.
A des degrés divers, la majeure partie des secteurs d’activités sont susceptibles de recourir au Big Data pour améliorer l’expérience de leurs clients, mais les plus avancés restent le e-commerce et la grande distribution, les opérateurs de services et le secteur financier.
Amazon, premier de la classe en Big Data
Les entreprises nord-américaines, et en particulier les pure players du Web, ont indéniablement une bonne longueur d’avance en matière d’exploitation commerciale du Big Data. Amazon s’est très tôt positionné en pionnier, avec son service de recommandations personnalisées, système de frappes chirurgicales qui vient se substituer avec succès au bazooka du couponing massif. Le géant du e-commerce peut s’appuyer sur une base de plus de 250 millions de clients, dont il cerne les goûts de plus en plus précisément en compilant des données structurées (déclaratif et navigation) et non structurées (contenus qu’ils stockent dans ses services de cloud). Amazon est ainsi capable de fournir à ses clients, en ligne ou via des campagnes d’e-mailing, des conseils personnalisés en temps réel susceptibles de se transformer en autant de commandes. La firme de Jeff Bezos a d’ailleurs une telle confiance dans la qualité de sa connaissance client qu’elle a déposé, début 2014, un brevet pour un nouveau système de livraison fondé sur l’anticipation des achats ! Ce dernier repose sur un algorithme, élaboré d’après les achats précédents du client, sa liste de souhaits, sa navigation sur le site et les produits qu’il a mis dans son panier sans les acheter.
Par ailleurs, non content de s’appuyer sur sa connaissance client pour accroître ses ventes, Amazon réfléchit désormais à la meilleure façon de monétiser de façon directe la mine d’or que représente ses données très qualifiées. Annoncé à l’été 2014, le service de publicité en ligne Amazon Sponsored Links n’a pas encore officiellement vu le jour, mais il ne devrait pas tarder à venir concurrencer Google Adsense.
En France, on a des idées… mais on peine encore à les concrétiser
Si 81% des dirigeants marketing interrogés dans le cadre de l’étude menée en France fin 2014 par Fullsix et Limelight sont « convaincus de la grande importance » du Big Data, seuls 18% ont déjà lancé des projets et 6% les ont vus aboutir…
Toutefois, si les entreprises françaises ne versent pas dans une stratégie tout-Big Data à la Amazon, elles ne négligent pas ses apports pour répondre à des problématiques plus ponctuelles.
La grande distribution s’affiche en pionnière, avec des enseignes qui cherchent à collecter autant d’informations que possible concernant leurs clients, en magasin avec la fameuse « digitalisation » du point de vente, mais aussi sur le Web et en mobilité. On retrouve l’idée du « vendre plus » dans la stratégie de la Fnac, qui optimise le ciblage de ses campagnes d’e-mailing en s’appuyant sur un modèle prédictif mettant à profit les informations recueillies concernant ses 20 millions de clients. Mais la dimension de l’anticipation est également au cœur de l’action des distributeurs, à l’image d’Auchan, qui s’est doté d’une solution d’analyse sémantique décortiquant en temps réel les verbatim clients déposés sur ses sites Web et ses comptes Facebook et Twitter. En traitant ce volume important de données non structurées, le distributeur extrait rapidement des informations stratégiques pour y répondre par des actions opérationnelles ciblées.
Voyages-SNCF mise sur le « vendre mieux », notamment avec des applications mobiles qui permettent de personnaliser l’expérience des usagers en facilitant leurs voyages. En fonction de leurs profils, ils se voient relayer en temps réel des informations importantes et proposer des services sur mesure.
Les opérateurs télécoms investissent tout particulièrement dans l’analyse prédictive des données, pour faire baisser leurs taux de churn. Ainsi, en surveillant la navigation des internautes sur ses sites Web, SFR réussirait, selon des chiffres récemment dévoilés, à repérer plus de 80% des candidats au départ, les contactant avant qu’ils aient pris leur décision… semble-t-il avec succès, puisque l’opérateur réussirait à en convaincre 3/4 de lui rester fidèle.
Enfin, le Big Data a également beaucoup à apporter aux entreprises du secteur financier. En permettant aux banques d’analyser en quelques minutes des masses de données qui nécessitaient auparavant plusieurs jours de décryptage, les technologies Big Data leur ouvrent la perspective d’une relation client plus immédiate et plus personnalisée. Le secteur de l’assurance peut s’appuyer sur les modèles prédictifs associés au Big Data, pour anticiper les risques (notamment liés au climat), ou encore développer de nouveaux business models, en matière d’assurance santé ou d’assurance automobile, à l’instar des offres « pay-as-you-drive » notamment mises en place par Direct Assurance.
Mais, les usages du Big Data ne sont pas tous liés au marketing et à la relation client… La suite au prochain numéro.